In October 2020, I wrote up the Salesforce Single VS Multi-Object Flow Field Update Benchmark where I simulated multiple conditions being evaluated but only one action being taken and see what the performance was in a single flow with multiple outcomes in 1 decision compared to multiple flows but each with only one criteria being evaluated each. Each flow in the original had no criteria in the start element and used a decision element in each to determine if any action should be taken.
With Salesforce making many Flow enhancements since Winter 21, I wanted to run these benchmarks again and compare them with a new benchmark that uses ordered multiple before-save flows with the criteria in the start element of each flow. I’m curious if the performance will be any better or not.
Methodology
Three custom objects were created. One for the single flow solution, another for the multiple flow solution with the run criteria in decision elements, and the third for multiple ordered flows with the criteria in each flow’s start. Each object has a custom text field named “Field To Update” along with 10 other text fields, “Field 1”, “Field 2”, … “Field 10”. The “Field To Update”‘s value specifies which other text field should have a default value specified. For example, if the “Field To Update”‘s value is “Field 10”, the system should set “Field 10″‘s value to the default value.
All these benchmarks were run on the Spring 22 release in a stand-alone developer org.
Single Flow & “Decision” Multiple Flow Methodologies
The first benchmark contains the single & “Decision” multiple flow methodologies.
Ordered Start Multiple Flow Methodology
10 before-save record create flows were created. One for each field that could be updated with a default value. Each flow’s start criteria checks for a specific “Field To Update” field value and if that criteria is met, the flow updates that designated field to a default value. For example, if the “Field To Update” is “Field 1”, here’s the flow that has a decision to see if that condition is true and assigns Field 1 a default value:
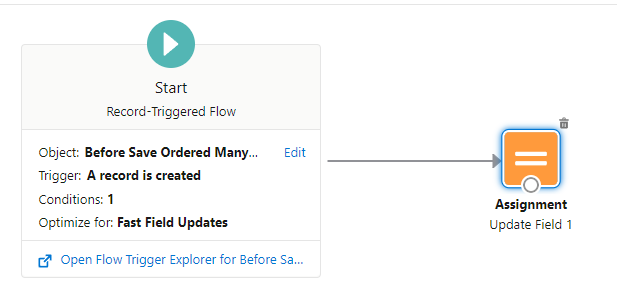
Start criteria:
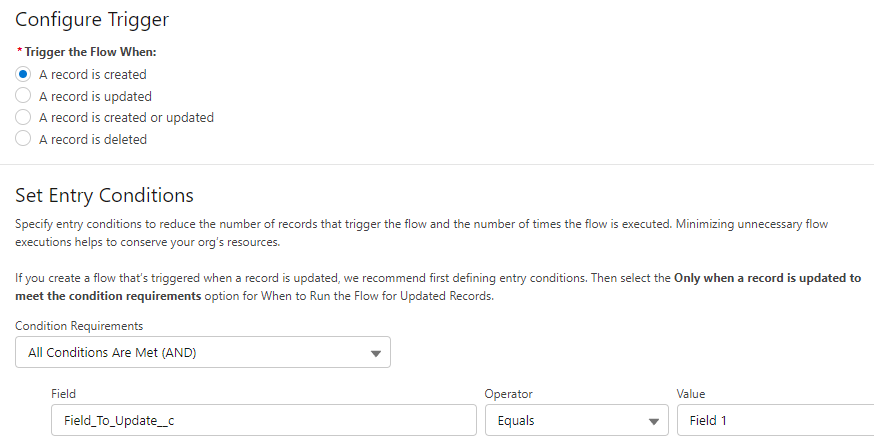
The assignment:
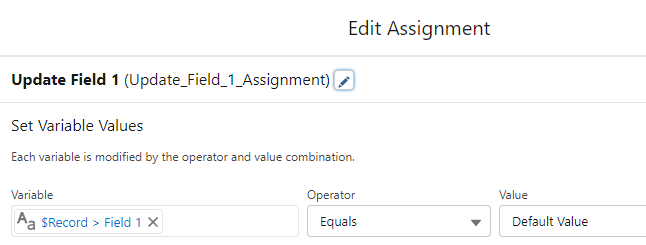
Each flow also is ordered 1-10 so that flow #1 will update Field 1, flow #2 will update Field 2, … , and Flow #10 will update Field #10.
The benchmark inserts 200 records whose “Field To Update” is set to “Field 10” using apex from Execute Anonymous using VS Code. Field 10 is used because it’s the last flow to execute and I wanted to ensure that all 10 flows are evaluated.
The start time in milliseconds is subtracted from the end time to determine the overall insertion time. These results are then recorded in a Benchmark Result custom object.
System.debug was avoided because turning on system.debug usually causes everything to be slower. Dan Appleman and Robert Watson shared that in their Dark Art of CPU Benchmarking presentation. Parsing each debug log after each benchmark run is also tedious.
The timings shown include the general overhead of inserting 200 records. As a result, the timings shouldn’t be interpreted as each operation takes X time. Each one is X plus Y overhead.
Benchmark Results
| “Ordered Start” Multiple Flow Average | Single Flow Average | “Decision” Multiple Flow Average |
| 85.7 milliseconds | 98.8 milliseconds | 263.7 milliseconds |
Disclaimer: These results are from a personal developer edition org running on the Spring 22 release. These timings will vary according to your edition, system load at the time, and other factors. Treat these as relative performance timings and not absolute timings.
Single Flow Results
| Run # | Time in Milliseconds |
| 1 | 100 |
| 2 | 96 |
| 3 | 97 |
| 4 | 106 |
| 5 | 97 |
| 6 | 96 |
| 7 | 100 |
| 8 | 98 |
| 9 | 91 |
| 10 | 107 |
Average: 98.8 milliseconds
Decision Multiple Flow Results
| Run # | Time in Milliseconds |
| 1 | 303 |
| 2 | 309 |
| 3 | 245 |
| 4 | 247 |
| 5 | 241 |
| 6 | 234 |
| 7 | 252 |
| 8 | 246 |
| 9 | 315 |
| 10 | 245 |
Average: 263.7 milliseconds
Ordered Start Multiple Flow Results
| Run # | Time in Milliseconds |
| 1 | 84 |
| 2 | 83 |
| 3 | 107 |
| 4 | 89 |
| 5 | 85 |
| 6 | 82 |
| 7 | 75 |
| 8 | 78 |
| 9 | 88 |
| 10 | 86 |
Average: 85.7 milliseconds
My Interpretation
The “Single Flow” vs “Decision” Multiple Flow timings are about the same as the first benchmark. The “Ordered Start” Multiple Flow was the fastest with an average of 85.7 milliseconds. I was expecting it to have performance similar to the “Decision” Multiple flow but it was even faster than the “Single Flow”!
My speculation is that having the criteria in the start element helps the Flow run-time decide which before-save flows to run and then only execute those. Since only 1 flow’s “Body” had to be executed, it runs much faster than the “Decision” Multiple flows since each flow’s “Body” is executed there and then determines if it should execute using its “Decision” element.
Conclusions
Originally, I wrote this as my guidance in the first benchmark:
Minimize Record Automation Flows Per Object. Each object should have as few record automation flows as possible. Use Before-Save flows for same-record field updates and use after save flows for everything else since before-save flows can’t do anything else as of Winter 21.
first benchmark
With the “Ordered Start” performing well, I’m revising my guidance slightly to:
Minimize Record Automation Flows Per Object. Each object should have as few record automation flows as possible. Use Before-Save flows for same-record field updates and use after save flows for everything else since before-save flows can’t do anything else as of Spring 22. Use Before-Save flows with the criteria in the start elements to determine which flows to run and to help manage complexity. However, still try to minimize the number of flows overall. If there’s a lot of automation, especially on heavily used standard objects like Accounts, Contacts, and Cases, use Apex triggers, if possible, since they have the best performance and lets one manage complexity more easily.