UPDATE: Benchmark Version 2 was done in the Spring 22 release and has some interesting updates.
A week or so ago, someone on the Salesforce Ohana Slack, which you should join, asked whether they should create one Object flow or multiple flows to populate some lookup fields when that record gets created. There use case was they had a “Transaction” object that’s generated when various source records from different objects were created and the transaction record should be tied to the appropriate source record. The challenge was it couldn’t be done when the transaction was created because it was from a managed package. This person mentioned that there were around 10 source objects generating transaction records. Following Salesforce best practices, one flow was created but it was already getting quite complex as expected and the person wondered if breaking them into separate flows would be acceptable.
Having recently done my own field update record automation benchmarking, this piqued my curiosity again. This time I wanted to simulate multiple conditions being evaluated but only one action being taken and see what the performance was in a single flow with multiple outcomes in 1 decision compared to multiple flows but each with only one criteria being evaluated each.
Want to run the benchmark? See my Salesforce Benchmark Package.
Methodology
Two custom objects were created. One for the single flow solution and the other for the multiple flow solution. Each object has a custom text field named “Field To Update” along with 10 other text fields, “Field 1”, “Field 2”, … “Field 10”. The “Field To Update”‘s value specifies which other text field should have a default value specified. For example, if the “Field To Update”‘s value is “Field 10”, the system should set “Field 10″‘s value to the default value.
Single Flow Methodology
One before record create flow was created to have a single Decision element with 10 outcomes.
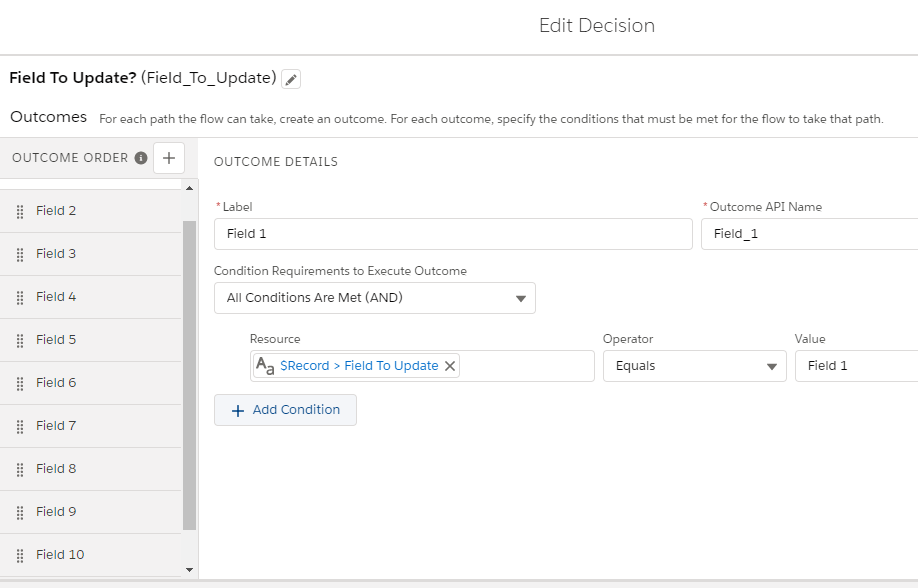
One outcome for each Field. Each one’s action is to assign a default value to that field. For example, when the “Field To Update” is assigned to “Field 10”, the Field 10 is assigned a default value.

The benchmark inserts 200 records whose “Field To Update” is set to “Field 10” using apex from Execute Anonymous using VS Code. Field 10 is used because it’s the last outcome in the decision and I wanted to ensure that all 10 conditions are evaluated to make it comparable to the multiple flows scenario. Otherwise, if “Field 1” was updated, it wouldn’t be comparable because outcomes 2-10 wouldn’t be evaluated.
The start time in milliseconds is subtracted from the end time to determine the overall insertion time. These results are then recorded in a Benchmark Result custom object.
System.debug was avoided because turning on system.debug usually causes everything to be slower. Dan Appleman and Robert Watson shared that in their Dark Art of CPU Benchmarking presentation. Parsing each debug log after each benchmark run is also tedious.
The timings shown include the general overhead of inserting 200 records. As a result, the timings shouldn’t be interpreted as each operation takes X time. Each one is X plus Y overhead.
Multiple Flows Methodology
With the multiple flows approach, 10 before create flows were created, one for each field that could be updated. Each flow has a decision that checks for a specific “Field To Update” field and assigns that field a default value if the condition is met. For example, if the “Field To Update” is “Field 1”, here’s the flow that has a decision to see if that condition is true and assigns Field 1 a default value:
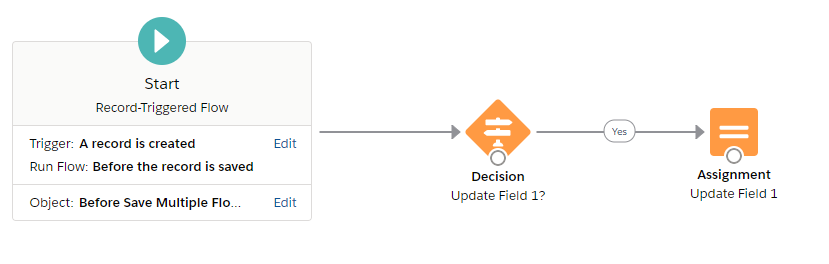
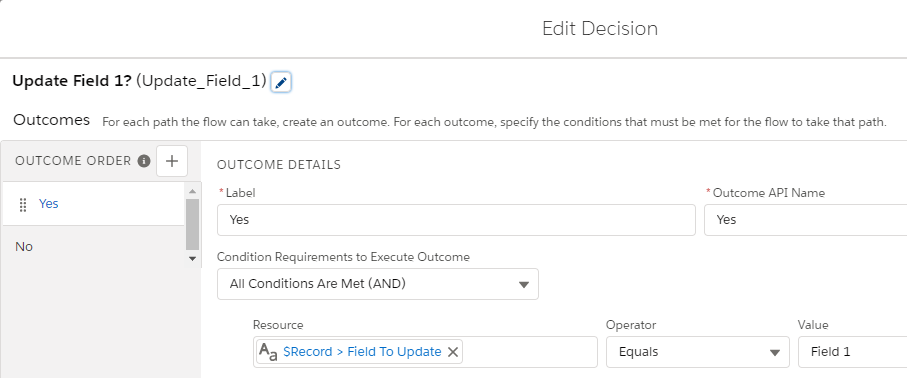
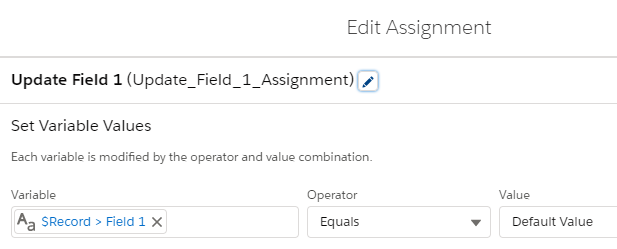
The benchmark inserts 200 records whose “Field To Update” is set to “Field 10” using apex from Execute Anonymous using VS Code. Field 10 is used because it’s the last outcome in the decision and I wanted to ensure that all 10 conditions are evaluated to make it as comparable to the multiple flows scenario. Otherwise, if “Field 1” was updated, it wouldn’t be comparable because outcomes 2-10 wouldn’t be evaluated.
The start time in milliseconds is subtracted from the end time to determine the overall insertion time. These results are then recorded in a Benchmark Result custom object.
System.debug was avoided because turning on system.debug usually causes everything to be slower. Dan Appleman and Robert Watson shared that in their Dark Art of CPU Benchmarking presentation. Parsing each debug log after each benchmark run is also tedious.
The timings shown include the general overhead of inserting 200 records. As a result, the timings shouldn’t be interpreted as each operation takes X time. Each one is X plus Y overhead.
Benchmark Results
Single Flow Vs Multiple Flow 10 Run Averages
| Single Flow Average | Multiple Flow Average |
| 87.2 Milliseconds | 286.4 milliseconds |
Disclaimer: These results are from a personal developer edition org running on the Winter 21 release. These timings will vary according to your edition, system load at the time, and other factors. Treat these as relative performance timings and not absolute timings.
Single Flow Results
| Run # | Time in Milliseconds |
| 1 | 82 |
| 2 | 105 |
| 3 | 85 |
| 4 | 79 |
| 5 | 90 |
| 6 | 78 |
| 7 | 99 |
| 8 | 105 |
| 9 | 73 |
| 10 | 76 |
Average: 87.2 Milliseconds
Multiple Flow Results
| Run # | Time in Milliseconds |
| 1 | 344 |
| 2 | 238 |
| 3 | 288 |
| 4 | 334 |
| 5 | 275 |
| 6 | 296 |
| 7 | 314 |
| 8 | 241 |
| 9 | 283 |
| 10 | 251 |
Average: 286.4 milliseconds
My Interpretation
Multiple flows take approximately 3 times longer than the single flow. My expectation was multiple flows would take longer. It’s hard to say why it takes longer. My speculation is that there’s quite a bit of overhead in the flow engine with multiple record automation flows on a single object. I’m also assuming that the single flow’s decision is evaluating all 10 outcomes so that it matches the 10 individual flows conditions being evaluated too.
Conclusions
- Minimize Record Automation Flows Per Object. Each object should have as few record automation flows as possible. Use Before-Save flows for same-record field updates and use after after flows for everything else since before-save flows can’t do anything else as of Winter 21.
- The new “Auto Layout” feature helps with the multiple outcome scenario since it creates a branch or path for each outcome. This helps with managing the complexity. I’m looking forward to the day when before-save flows can have sub-flows which will help even further. Your mileage will vary with the Auto Layout.
Stay tuned for an upcoming blog post detailing how you can get the code for this benchmark.
What do you think of these results? Let us know in the comments below.
Luke,
We really appreciate this work. It’s part of our considerations while moving from workflow rules to flows. We are curious if you benchmarked the multi-flow approach with the criteria in the Start node instead of a decision element after the Start node. It seems like that would improve performance. We were keen to use a single flow for same-record updates, but then noticed that in the upcoming release we are now able to dictate flow trigger order. So, we are now considering going with multiple flows, but not if the performance isn’t as good.
Andy,
That crossed my mind too. Now that the Spring release is here, I’ll check that out and create a blog post for it. Stay tuned.
Andy,
Here’s an updated benchmark using the start element for each flow and the trigger order. Let me know what you think of this: https://metillium.com/2022/02/salesforce-single-vs-multi-object-flow-field-update-benchmark-v2/