Recently, someone in the Ohana Slack, which you should join, asked why start criteria wasn’t used in the Single VS Multi-Object Flow Field Update Benchmark and my reply was it was due my curiosity for that particular use case. However, this piqued my interest in what the Before Save Flow performance is between having one on an Object with a Start Criteria and Multiple Before Save Flows Each With Start Criteria on an Object.
Methodology
Two custom objects were created. One for the single before save flow with a start criteria and the other with ten before save flows each with a start criteria. Each custom object has a custom text field named “Field To Update” along with 100 other text fields, “Field 1”, “Field 2”, … “Field 100”. The “Field To Update”‘s value specifies which other text field should have a default value specified. For example, if the “Field To Update”‘s value is “Field 10”, the system should set “Field 10″‘s value to the default value.
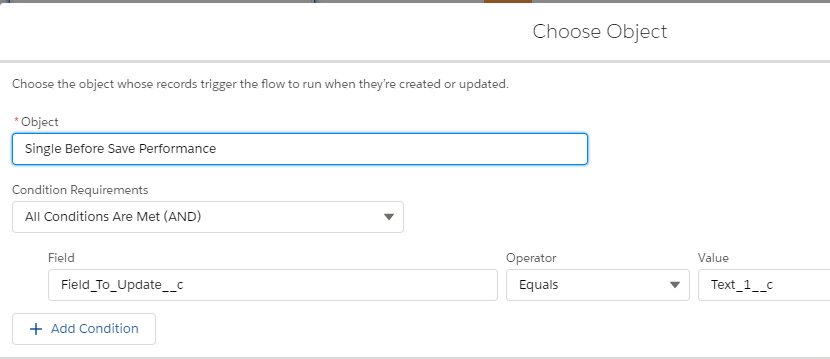
Single Before Save With Start Criteria Flow Methodology
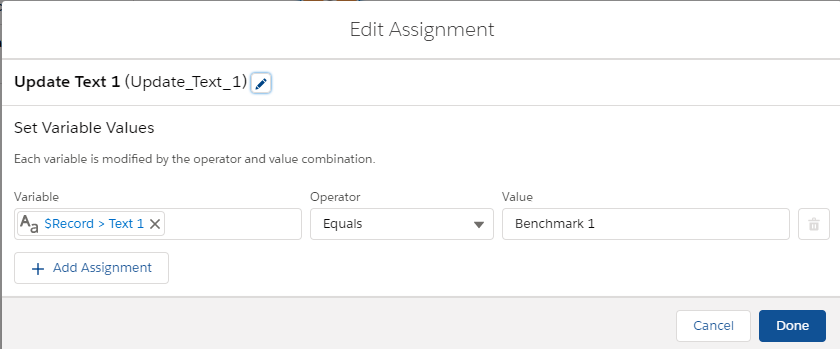
One before record create flow was created with a start criteria. If the start criteria is met, it assigns a default value to the field. In particular, when the “Field To Update” is “Text_1__c”, the default value “Benchmark 1” is assigned to the “Text_1__c” field.
The benchmark inserts 200 records whose “Field To Update” is set to “Text_1__c” using apex from Execute Anonymous using VS Code. The start time in milliseconds is subtracted from the end time to determine the overall insertion time. Test results are then recorded in a Benchmark Result custom object.
System.debug was avoided because turning on system.debug usually causes everything to be slower. Dan Appleman and Robert Watson shared that in their Dark Art of CPU Benchmarking presentation. Parsing each debug log after each benchmark run is also tedious.
The timings shown include the general overhead of inserting 200 records. As a result, the timings shouldn’t be interpreted as each operation takes X time. Each one is X plus Y overhead.
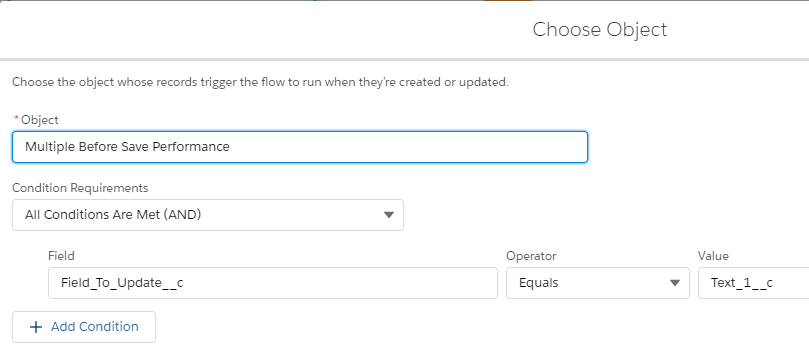
Multiple Before Save Each With Start Criteria Flows Methodology
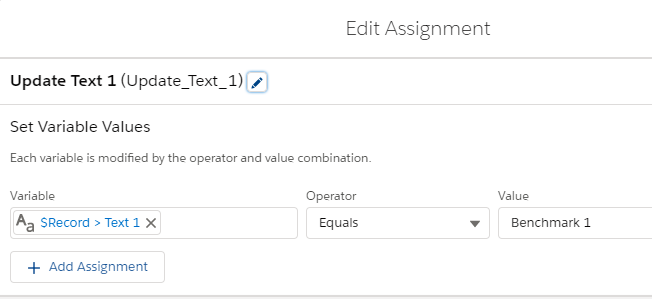
With the multiple flows approach, 10 before create flows were created, one for each of 10 fields to default a value for. Each flow has a start criteria that checks for a specific “Field To Update” and assigns a default value to the desired field if the condition is met. For example, if the “Field To Update” is “Text_1__c”, the default value “Benchmark 1” is assigned to “Text_1__c”. Below is the criteria and the assignment for that use case. The other nine (2-10) are omitted for brevity.
The benchmark inserts 200 records whose “Field To Update” is set to “Text_1__c” using apex from Execute Anonymous using VS Code. The start time in milliseconds is subtracted from the end time to determine the overall insertion time. Test results are then recorded in a Benchmark Result custom object.
System.debug was avoided because turning on system.debug usually causes everything to be slower. Dan Appleman and Robert Watson shared that in their Dark Art of CPU Benchmarking presentation. Parsing each debug log after each benchmark run is also tedious.
The timings shown include the general overhead of inserting 200 records. As a result, the timings shouldn’t be interpreted as each operation takes X time. Each one is X plus Y overhead.
Benchmark Results
Single Flow With Start Criteria VS Multiple Flows Each With Start Criteria 10 Run Averages
| Single Flow With Start Criteria Average | Multiple Flows Each With Start Criteria Average |
| 165.7 Milliseconds | 286 Milliseconds |
Disclaimer: These results are from a personal developer edition org running on the Spring 21 release. These timings will vary according to your edition, system load at the time, and other factors. Treat these as relative performance timings and not absolute timings.
Single Before Save Flow With Start Criteria Results
| Run # | Time in Milliseconds |
| 1 | 161 |
| 2 | 168 |
| 3 | 157 |
| 4 | 168 |
| 5 | 174 |
| 6 | 141 |
| 7 | 162 |
| 8 | 173 |
| 9 | 158 |
| 10 | 195 |
Average: 165.7 Milliseconds
Multiple Before Save Flows Each With Start Criteria Results
| Run # | Time in Milliseconds |
| 1 | 329 |
| 2 | 271 |
| 3 | 265 |
| 4 | 275 |
| 5 | 282 |
| 6 | 319 |
| 7 | 269 |
| 8 | 283 |
| 9 | 291 |
| 10 | 276 |
Average: 286 Milliseconds
My Interpretation
Having 10 before save flows compared to One with a start criteria takes approximately 2 times longer. That’s not bad considering there are 10 times as many before save flows but in each scenario, only 1 of its actions are running.
This begs the question…. Should we still minimize the number of flows and evaluate the criteria in a decision? Let’s run the Single Vs Multi-Object Flow Field Update Benchmark Again and compare its results to these to draw some conclusions.
Single Flow Without Start Criteria Using A Decision With 10 Outcomes To Evaluate Field To Update
| Run # | Time In Milliseconds |
| 1 | 98 |
| 2 | 75 |
| 3 | 96 |
| 4 | 97 |
| 5 | 112 |
| 6 | 82 |
| 7 | 95 |
| 8 | 75 |
| 9 | 132 |
| 10 | 102 |
Average: 96.7 Milliseconds
Multiple Flows Each Without Start Criteria Each With One Decision With One Outcome To Evaluate Field To Update
| Run # | Time In Milliseconds |
| 1 | 320 |
| 2 | 394 |
| 3 | 387 |
| 4 | 294 |
| 5 | 311 |
| 6 | 342 |
| 7 | 308 |
| 8 | 427 |
| 9 | 298 |
| 10 | 261 |
Average: 334.2 Milliseconds.
| Single Decision No Start Average | Single Start No Decision Average | Multiple With One Decision Average | Multiple With Start Criteria Average |
| 96.7 Milliseconds | 161 Milliseconds | 334.2 Milliseconds | 286 Milliseconds |
These results are interesting. The Single Before Create Save flow without any criteria but with one decision to evaluate 10 outcomes has an average time of 96.7 milliseconds. Another Single Before Create Save flow that has start criteria to evaluate if the field to update is a single value has an average time of 161 milliseconds. That was surprising because I would think it would be reversed because the start criteria only has one set of criteria to evaluate whereas the decision has 10 criteria to evaluate!
Conclusions
Minimize Record Automation Flows Per Object. Each object should have as few record automation flows as possible. Ideally, there should be only one before-save flow that uses decisions to evaluate the actions to take. Before-Save flows only allow one to query related parent records and to update the record’s values so use After Save flows for all other automation. Ideally, there is only one after-save flow that uses decisions to evaluate the actions to take. Since after-save flows can use sub-flows, delegate complex logic to them to keep the after-save flow lean and essentially be the “orchestrator”. After-Save flows don’t allow sub-flows today but that would be the ideal way. Keeping all the functionality in one after-save flow may be too complex depending on your needs. My Sub-Flow Invocation Alternatives has some options that may help with that but consider the tradeoffs!
Since after-save flows can’t use sub-flows yet , so your conclusion statement is not correct.
Daniel,
Thanks for the correction! That is accurate. I’ve updated the post.
Subflows are possible within after-save flows with winter 22