After Test Summary
I Passed! Overall, this one was a little trickier than I expected. It had more governance related questions than I expected and I need to learn more on that topic overall. Definitely ensure you study center of excellence, Master Data Management, and other related governance areas!
Overview
Here’s my study guide used to prepare for the Data Architecture & Management certification exam. Certain topics like Visualforce and other areas I’m well versed in are excluded. Review the Resource Guide for a complete prep resource list.
Data Architecture & Management Details Guide
Resource Guide – Lists all the resources used to prepare.
Sources
- Large Data Volume Best Practices
- Bulk API – Maximizing Parallelism and Throughput Performance When Integrating or Loading Large Data Volumes
- Salesforce Backup & Restore Series
- Query & Search Optimization Cheat Sheet
- Record Locking Cheatsheet
- Salesforce Memo Blog Post
- Always A Blezard
Exam Outline
- Data Modeling – 20%
- Conceptual Design – 15%
- Master Data Management – 10%
- Metadata Management – 7%
- Data Archiving – 10%
- Data Governance – 7%
- Business Intelligence, Reporting & Analytics – 10%
- Data Migration – 10%
- Performance Tuning – 10%
Large Data Volumes
“Large data volume is a loosely defined term but if your deployment has tens of thousands of users, millions of records, or hundreds of gigabytes of total record storage, then you have large data volumes”. Source
Operations Affected By Large Data Volumes
- Inserting or Updating Large numbers of records
- Querying through SOQL, Reports, List Views, etc
Optimization Strategies
- Follow Industry Best Practices for schema changes and operations in database-enabled applications
- Deferring or bypassing business rule and sharing processing
- Choosing the most efficient operation for accomplishing a task
Search Architecture
Search is the capability to query records based on free-form text. The search database has its own data store that is optimized for search. This is what SOSL queries against.
Query Optimizer
Salesforce uses its own database query optimizer using statistics to determine the best query plan to use based on the lowest cost plan. In brief, it tries to use the query that has an index(es) under the selectivity threshold. Otherwise, it has to do a table scan. May be able to use sharing tables to drive the query too.
Query Plan
Can use the “Query Plan” feature of the Developer Console to try this out. Queries with a cost less than 1 use an index or have a very low number of records.
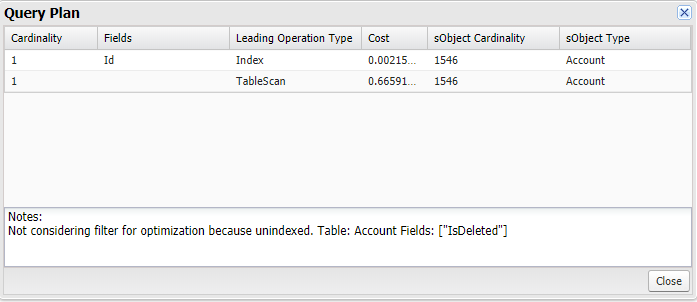
- Cardinality – Estimated number of records the leading operation would return
- Fields – The indexed fields used by the query.
- Leading Operation Type – operation type Saleforce will use to optimize the query
- Index – will use an index on the object
- Other – query will use other optimizations internal to Salesforce
- Sharing – query will use an index based on the sharing rules associated with the user executing the query.
- TableScan – query will scan all records in object.
- Notes – One or more feedback notes.
- Cost – cost of the query compared to the query optimizer’s selectivity threshold. Values above 1 mean that the query won’t be selective.
- sObject Cardinality – Approximate record count for the object
- sobject Type – The name of the query object.
Selectivity Threshold Rules
The following rules determine when the query optimizer will use indexes. Note: soft-deleted records are counted in the total number of records.
- Standard Index
- 30% of first million records plus 15% over 1 million up to a max of 1 million records.
- Custom Index
- 10% of total records up to a max of 333,333 records.
- AND clause – uses the indexes unless one of them returns more than 20% of the object’s records or 666,666 total records.
- OR clause – uses the indexes unless they all return more than 10% of the object’s records or 333,333 total records.
- Like clause – statistics aren’t used. A sample of up to 100,000 records of actual data are used to decide whether to use a custom index.
Index Selectivity Exceptions
- Negative Filter Operators
- !=
- Not Like
- Excludes
- Comparison Operators paired with text fields
- text_field <, >, <=, >=
- Leading % wildcards
- References to non-deterministic fields
Skinny Tables
A Skinny Table is a separate table that Salesforce can create to contain frequently used fields in order to avoid joins. Salesforce basically replicates the data from their source tables and keeps it in sync and then uses it where appropriate. If a query can use all the fields from it, then it’s much faster since all the data is in one table. They are most efficient with objects with millions of records to improve the performance of readonly operations.
They can be created on
- Account
- Contact
- Opportunity
- Lead
- Case
- Custom Objects
Supported Field Types
- Checkbox
- Data
- Date Time
- Number
- Percent
- Phone
- Picklist (multi-select)
- Text
- Text area
- Text area (long)
- URL
Considerations
- Maximum of 100 columns
- No fields from other objects
- Only copied to Full Sandboxes from Production. Not copied to non-Full sandboxes automatically. Have to contact support for non-Full sandboxes.
Indexes
Salesforce supports custom indexes to speed up queries, and one can create custom ones by contacting support. By default, indexes don’t have nulls in them unless support explicitly enables them.
Note: Custom Indexes created in production are copied to all sandboxes created from production.
Standard Indexed Fields
- RecordTypeId
- Division
- CreatedDate
- Systemmodstamp (LastModifiedDate)
- Name
- Email for Contacts and Leads
- Lookups and Master-Details
- Id aka Salesforce unique record id
- External Ids. They can be created on
- Auto Number
- Number
- Text
Custom Indexes
Salesforce can create custom indexes on standard and custom fields.
They can also be created on deterministic formula fields! If a formula is changed after the index is created, the index is disabled and support has to be contacted to have it reenabled.
Ineligible Types for Custom Indexes
- Multi-select Picklists
- Long Text Area
- Rich Text Area
- Encrypted Text Fields
- Non-Deterministic Formulas – A non-deterministic formula is one that has either a cross-object reference either directly or indirectly through another embedded formula OR references a dynamic date time such as Today() or Now(). Additional non-deterministic formula fields:
- Owner, autonumber, division, audit fields except createddate and createdbyid
- Multi-select picklists
- Currency Fields in multi-currency orgs
- Long Text Areas
- Binary Fields
- Standard Fields with special functions
- Opportunity: Amount, TotalOpportunityQuantity, ExpectedRevenue, IsClosed, IsWon
- Case: ClosedDate, IsClosed
- Product: ProductFamily, IsActive, IsArchived,
- Solution: Status
- Lead: Status
- Activity: Subject, TaskStatus, TaskPriority
Optimization Techniques
- Mashups
- Defer Sharing Calculation
- Using SOQL and SOSL
- Deleting Data
- Search
Best Practices
- Limit number of records stored.
- Keep queries lean and selective.
- Use Bulk API when dealing with large numbers of records.
- On Update: only send the changed fields.
- For initial load:
- Use Public Read / Write OWDs to avoid sharing calculations
- Reduce the amount of work to do by disabling validation rules, workflow rules, process builders, triggers, etc. Note: May have to run post import validation reports and analysis to inspect data quality and repair if needed.
- Populate Roles before populating sharing rules
- If possible, add people and data before creating and assigning groups and queues.
- SOQL
- Split a query into multiple queries in order to use indexes, if needed.
- Avoid querying on formula fields
- Use the appropriate query mechanism: SOQL or SOSL.
- Avoid Data Skew. Data Skew is when a very large number of child records are associated with a single record. Avoid this by keeping the number of child records to less than 10,000 on a single parent record.
- Avoid Ownership Skew.
Backup & Restore Essentials
One can backup Data and Metadata.
APIs
- REST, SOAP, Bulk for Data
- Metadata API for Metadata
Backup Strategies
| Backup Type | Comments | Pros | Cons |
|---|---|---|---|
| Full |
|
|
|
| Incremental |
|
|
|
| Partial |
|
|
|
Can Mix and match these. For example, weekly full backups, daily incremental, monthly partials.
Backup Optimization Principles
| Vertical optimization | Backup time is, among other parameters, proportional to the number of records you are retrieving.
Splitting vertically your query into several queries to reduce the number of records included per query can bypass several incidents like timeouts or other limits (for example, in Spring `15 a single Bulk query can only generate up to 15GB of data). This approach can be efficient if taking into account how the Force.com Query Optimizer works. Using PK Chunking is one very efficient way of splitting a query vertically. Partial backup is also a type of vertical optimization. |
| Horizontal optimization | Backup time is, among other parameters, proportional to the number and types of columns you are retrieving. Text areas (and other large fields) are fields that can really slow down a backup to the point of timeout.
Splitting horizontally your query into several queries, to reduce the number of fields included per query, will avoid several issues like timeouts or query size limit (i.e. in Spring `15, by default, SOQL statements cannot exceed 20,000 characters in length). Removing fields from the query (i.e. calculated fields) is also a type of horizontal optimization. |
Bulk API
Asynchronous API used to load or query large data volumes. Doesn’t count against API limit but has other limits.
Primary Key (PK) Chunking to Extract Large Data Sets
With this method, customers first query the target table to identify a number of chunks of records with sequential IDs. They then submit separate queries to extract the data in each chunk, and finally combine the results. This is used with large data sets that exceed the selectivity index.